UTF-8 转 GBK 的悲剧:特殊字符 C2A0
02 May 2011问题表现
闪印发布后经常会发现传给印象派的作品描述 XML(GBK 编码) 中一些文字信息经常包含乱码,而且会一乱到底,甚至导致不同页的错乱。刚开始一直都没有什么头绪,后来终于发现了问题所在:GBK 的字符集过小,对一些特殊字符的转码会出现乱码。一些生僻字也就算了,但是其中却包括这个字符 C2A0————一个在网页上经常使用排版用全角空格。用户从网页端拷贝了一段包含此字符的字符串,复制到界面上显示正常,保存到作品 XML 文件中 (UTF8 编码),显示正常。但是上传作品时由于将相应的 XML 编码格式转换成 GBK,于是出现了乱码。
处理方法
方法一:转换时对文本信息做特殊处理,用 0×20 代替掉 0xC2A0。 方法二:作品 XML 文件直接以 UTF8 编码传输。
方法一有点头疼治头脚疼治脚的味道,虽然解决了这个问题,但是总归不够规范不够完美—- 很多页面都是这么做。而方法二则需要服务器支持,但可以完美的解决这个问题。以前服务器之所以用 GBK 编码很大的理由可能在于 GBK 相对 UTF8 更省空间—- 在这么个硬盘空间足够,带宽足够的现状下,节约出来的那么点东西又有什么用呢?
还有一个值得一提的问题是 GBK 对字符解析失败引起的问题是有多米诺骨牌效应的:UTF8 编码的字符第一个字节有且只有六种可能:(如图)
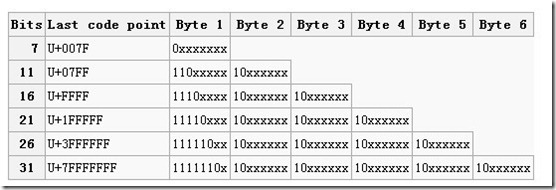
而 GBK 则没有这样的便利,在解析第一个字节出错后,并没有任何规则来说明后续的那个字节到底是上一个错误字符的一部分,还是下一个字符的起始字符。默认的处理是将解析出错的字节标注为 0x3F(即?),下一个字节作为下一个字符的起始位置来进行解析。这样的规则就很容易引起后续的解析全部出错。